automating probabilistic inference and learning
publications
- tl;dr: We show that standard vision-language models fail under covariate shift and propose VLC, a neuro-symbolic approach that combines learned perception with exact symbolic circuits to achieve robust visual reasoning.[ paper | bibtex | abstract ]
Vision-Language Models (VLMs) have been applied to a wide range of reasoning tasks, yet it remains unclear whether they can reason robustly under distribution shifts. In this paper, we study covariate shifts in which the perceptual input distribution changes while the underlying prediction rules do not. To investigate this question, we consider visual deductive reasoning tasks, where a model is required to answer a query given an image and logical rules defined over the object concepts in the image. Empirically, we find that VLMs fine-tuned through gradient-based end-to-end training can achieve high in-distribution accuracy but fail to generalize under such shifts, suggesting that fine-tuning does not reliably induce the underlying reasoning function. This motivates a neuro-symbolic perspective that decouples perception from reasoning. However, we further observe that recent neuro-symbolic approaches that rely on black-box components for reasoning can still exhibit inconsistent robustness across tasks. To address this issue, we propose VLC, a neuro-symbolic method that combines VLM-based concept recognition with circuit-based symbolic reasoning. In particular, task rules are compiled into a symbolic program, specifically a circuit, which executes the rules exactly over the object concepts recognized by the VLM. Experiments on three visual deductive reasoning tasks with distinct rule sets show that VLC consistently achieves strong performance under covariate shifts, highlighting its ability to support robust reasoning.@misc{chen2026vlmsreasonrobustlyneurosymbolic, title={Can VLMs Reason Robustly? A Neuro-Symbolic Investigation}, author={Weixin Chen and Antonio Vergari and Han Zhao}, year={2026}, eprint={2603.23867}, archivePrefix={arXiv}, primaryClass={cs.LG}, url={https://arxiv.org/abs/2603.23867}, }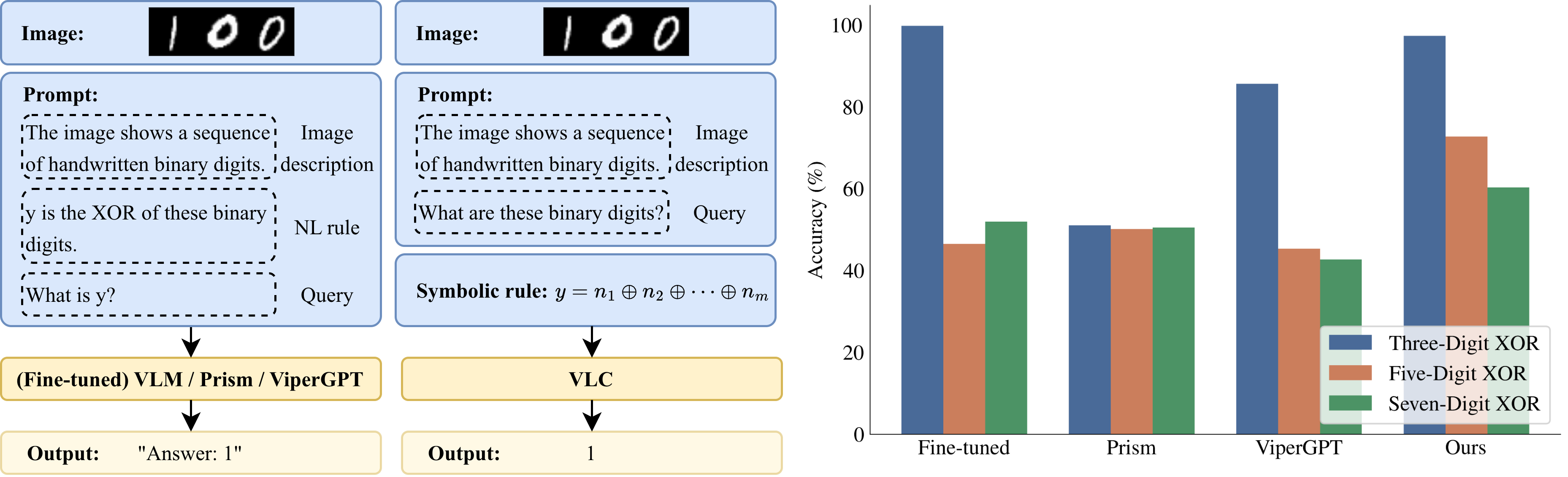
- tl;dr: We highlight the limitations of current protocols to evaluate the fidelity of synthetic tabular data, and introduce probabilistic circuits as a baseline method for tabular data generation, delivering competitive or superior performance to SotA models for a fraction of the cost.[ paper | bibtex | abstract ]
Tabular data is more challenging to generate than text and images, due to its heterogeneous features and much lower sample sizes. On this task, diffusion-based models are the current state-of-the-art (SotA) model class, achieving almost perfect performance on commonly used benchmarks. In this paper, we question the perception of progress for tabular data generation. First, we highlight the limitations of current protocols to evaluate the fidelity of generated data, and advocate for alternative ones. Next, we revisit a simple baseline -- hierarchical mixture models in the form of deep probabilistic circuits (PCs) -- which delivers competitive or superior performance to SotA models for a fraction of the cost. PCs are the generative counterpart of decision forests, and as such can natively handle heterogeneous data as well as deliver tractable probabilistic generation and inference. Finally, in a rigorous empirical analysis we show that the apparent saturation of progress for SotA models is largely due to the use of inadequate metrics. As such, we highlight that there is still much to be done to generate realistic tabular data. Code available at this https URL.@misc{scassola2026soberinglooktabulardata, title={A Sobering Look at Tabular Data Generation via Probabilistic Circuits}, author={Davide Scassola and Dylan Ponsford and Adrián Javaloy and Sebastiano Saccani and Luca Bortolussi and Henry Gouk and Antonio Vergari}, year={2026}, eprint={2603.23016}, archivePrefix={arXiv}, primaryClass={cs.LG}, url={https://arxiv.org/abs/2603.23016}, }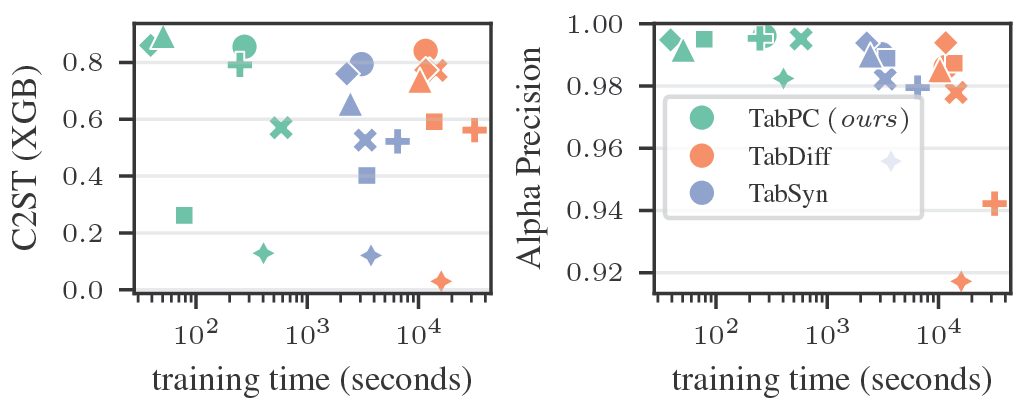
- tl;dr: We optimize orthogonal matrices with 5 matrix multiplications per iteration, beating in minutes baselines that take hours.[ paper | bibtex | abstract ]
Orthogonality constraints are ubiquitous in robust and probabilistic machine learning. Unfortunately, current optimizers are computationally expensive and do not scale to problems with hundreds or thousands of constraints. One notable exception is the Landing algorithm (Ablin et al., 2024) which, however comes at the expense of temporarily relaxing orthogonality. In this work, we revisit and improve on the ideas behind Landing, enabling the inclusion of modern adaptive optimizers while ensuring that orthogonal constraints are effectively met. Remarkably, these improvements come at little to no cost, and reduce the number of required hyperparemeters. Our algorithm POGO is fast and GPU-friendly, consisting of only 5 matrix products, and in practice maintains orthogonality at all times. On several challenging benchmarks, POGO greatly outperforms recent optimizers and shows it can optimize problems with thousands of orthogonal matrices in minutes while alternatives would take hours. As such, POGO sets a milestone to finally exploit orthogonality constraints in ML at scale. A PyTorch implementation of POGO is publicly available at this https URL.@misc{javaloy2026embarrassinglysimplewayoptimize, title={An Embarrassingly Simple Way to Optimize Orthogonal Matrices at Scale}, author={Adrián Javaloy and Antonio Vergari}, year={2026}, eprint={2602.14656}, archivePrefix={arXiv}, primaryClass={cs.LG}, url={https://arxiv.org/abs/2602.14656}, }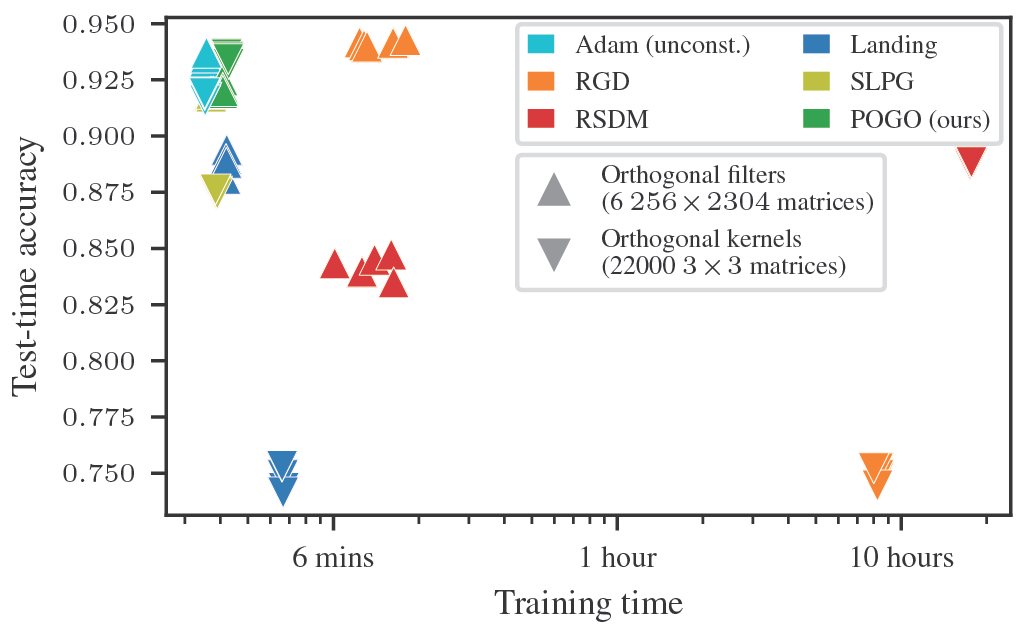
- tl;dr: We investigate under which conditions we can perform constrained MAP inference over continuous variables exactly and efficiently—via a message-passing algorithm—and introduce a general approach that alternates convex partitioning with numerical optimisation.[ paper | bibtex | abstract ]
In many safety-critical settings, probabilistic ML systems have to make predictions subject to algebraic constraints, e.g., predicting the most likely trajectory that does not cross obstacles. These real-world constraints are rarely convex, nor the densities considered are (log-)concave. This makes computing this constrained maximum a posteriori (MAP) prediction efficiently and reliably extremely challenging. In this paper, we first investigate under which conditions we can perform constrained MAP inference over continuous variables exactly and efficiently and devise a scalable message-passing algorithm for this tractable fragment. Then, we devise a general constrained MAP strategy that interleaves partitioning the domain into convex feasible regions with numerical constrained optimization. We evaluate both methods on synthetic and real-world benchmarks, showing our approaches outperform constraint-agnostic baselines, and scale to complex densities intractable for SoTA exact solvers.@misc{kurscheidt2026mapinference, title={The Theory and Practice of MAP Inference over Non-Convex Constraints}, author={Leander Kurscheidt and Gabriele Masina and Roberto Sebastiani and Antonio Vergari}, year={2026}, eprint={2602.08681}, archivePrefix={arXiv}, primaryClass={cs.LG}, url={https://arxiv.org/abs/2602.08681}, }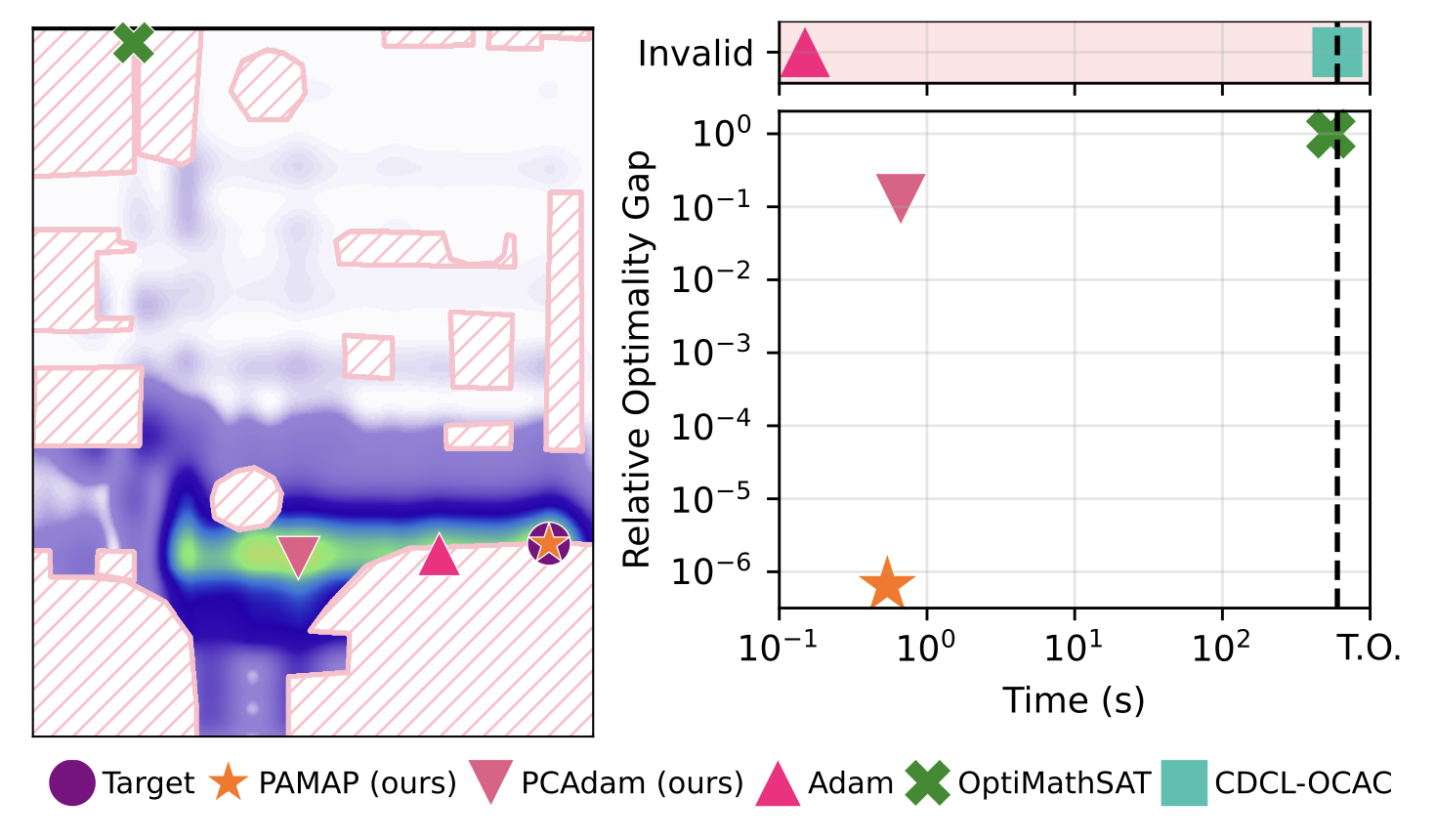
- tl;dr: We compile Description Logic ontologies into differentiable circuits to enable scalable reasoning, generate data, and build neuro-symbolic models that produce reliable, ontology-consistent predictions.[ paper | bibtex | abstract ]
Background: Neuro-symbolic methods enhance the reliability of neural network classifiers through logical constraints, but they lack native support for ontologies. Objectives: We aim to develop a neuro-symbolic method that reliably outputs predictions consistent with a Description Logic ontology that formalizes domain-specific knowledge. Methods: We encode a Description Logic ontology as a circuit, a feed-forward differentiable computational graph that supports tractable execution of queries and transformations. We show that the circuit can be used to (i) generate synthetic datasets that capture the semantics of the ontology; (ii) efficiently perform deductive reasoning on a GPU; (iii) implement neuro-symbolic models whose predictions are approximately or provably consistent with the knowledge defined in the ontology. Results We show that the synthetic dataset generated using the circuit qualitatively captures the semantics of the ontology while being challenging for Machine Learning classifiers, including neural networks. Moreover, we show that compiling the ontology into a circuit is a promising approach for scalable deductive reasoning, with runtimes up to three orders of magnitude faster than available reasoners. Finally, we show that our neuro-symbolic classifiers reliably produce consistent predictions when compared to neural network baselines, maintaining competitive performances or even outperforming them. Conclusions By compiling Description Logic ontologies into circuits, we obtain a tighter integration between the Deep Learning and Knowledge Representation fields. We show that a single circuit representation can be used to tackle different challenging tasks closely related to real-world applications.@misc{lazzari2026neurosymbolicclassificationcompilingdescription, title={To Neuro-Symbolic Classification and Beyond by Compiling Description Logic Ontologies to Probabilistic Circuits}, author={Nicolas Lazzari and Valentina Presutti and Antonio Vergari}, year={2026}, eprint={2601.14894}, archivePrefix={arXiv}, primaryClass={cs.AI}, url={https://arxiv.org/abs/2601.14894}, }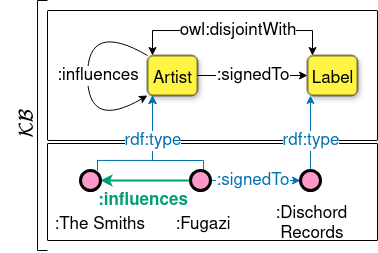
- tl;dr: We introduce RTCE, a new benchmark which shows that even state-of-the-art code LLMs struggle to maintain consistent reasoning between forward and reverse execution, highlighting a lack of true round-trip coherence.[ paper | bibtex | abstract ]
LLMs demonstrate strong performance on code benchmarks, yet round-trip code execution reveals limitations in their ability to maintain consistent reasoning across forward and backward execution. We present RoundTripCodeEval (RTCE), a comprehensive benchmark consisting of four distinct code execution reasoning tasks designed to rigorously test round-trip consistency. RTCE provides an execution-free, exact-match evaluation of bijection fidelity, assessing whether models preserve a consistent one-to-one mapping between encoding and decoding operations across various algorithms and directions. We systematically evaluate state-of-the-art Code-LLMs using zero-shot prompting, supervised fine-tuning on execution traces, and self-reflection mechanisms. Each yields modest improvements, but none closes the gap, indicating that current LLMs struggle with true round-trip consistency, which demonstrates that they lack the internal coherence required for trustworthy code reasoning. RTCE surfaces several new and previously unmeasured insights that are not captured by existing I/O-prediction, execution-reasoning, or round-trip natural-language benchmarks. We will release the code and the dataset upon acceptance.@misc{maveli2026llmscompressanddecompress, title={Can LLMs Compress (and Decompress)? Evaluating Code Understanding and Execution via Invertibility}, author={Nickil Maveli and Antonio Vergari and Shay B. Cohen}, year={2026}, eprint={2601.13398}, archivePrefix={arXiv}, primaryClass={cs.LG}, url={https://arxiv.org/abs/2601.13398}, }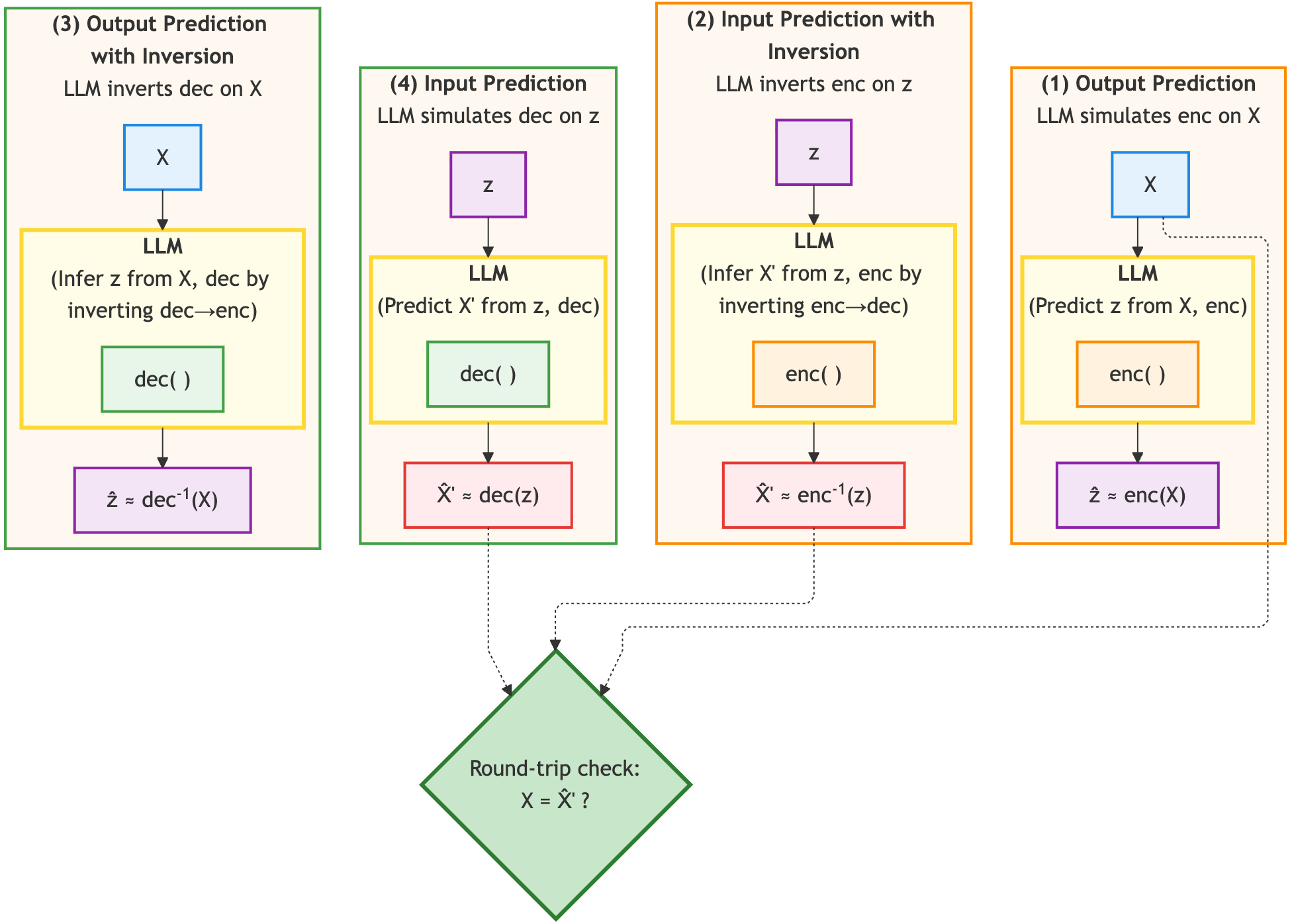
- tl;dr: We derive novel circuit properties based on orthogonality to speed-up marginalization in squared circuits and tensor network-based Born machines, as well as to unlock a strictly larger set of factorization structures enabling tractable marginalization[ paper | bibtex | abstract ]
Squared tensor networks (TNs) and their extension as computational graphs--squared circuits--have been used as expressive distribution estimators, yet supporting closed-form marginalization. However, the squaring operation introduces additional complexity when computing the partition function or marginalizing variables, which hinders their applicability in ML. To solve this issue, canonical forms of TNs are parameterized via unitary matrices to simplify the computation of marginals. However, these canonical forms do not apply to circuits, as they can represent factorizations that do not directly map to a known TN. Inspired by the ideas of orthogonality in canonical forms and determinism in circuits enabling tractable maximization, we show how to parameterize squared circuits to overcome their marginalization overhead. Our parameterizations unlock efficient marginalization even in factorizations different from TNs, but encoded as circuits, whose structure would otherwise make marginalization computationally hard. Finally, our experiments on distribution estimation show how our proposed conditions in squared circuits come with no expressiveness loss, while enabling more efficient learning.@misc{loconte2025square,
title={How to Square Tensor Networks and Circuits Without Squaring Them},
author={Lorenzo Loconte and Adrián Javaloy and Antonio Vergari},
year={2025},
eprint={2512.17090},
archivePrefix={arXiv},
primaryClass={cs.LG}}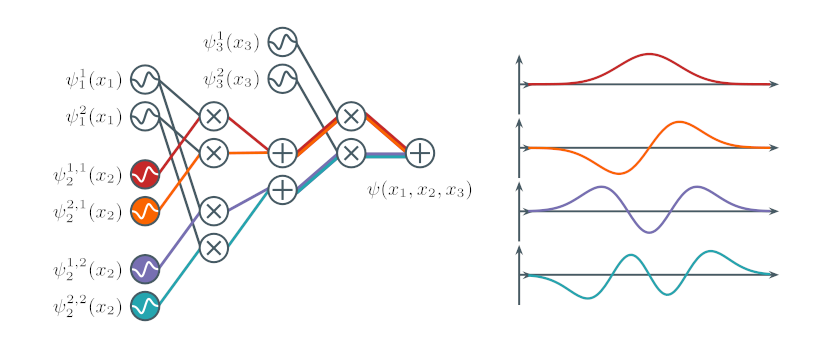
- tl;dr: We propose a framework for multi-token prediction using speculative decoding, allowing us to easily explore different parameterizations balancing expressiveness and efficiency, and generalize other approaches based on tensor factorizations.[ paper | bibtex | abstract ]
Multi-token prediction (MTP) is a prominent strategy to significantly speed up generation in large language models (LLMs), including byte-level LLMs, which are tokeniser-free but prohibitively slow. However, existing MTP methods often sacrifice expressiveness by assuming independence between future tokens. In this work, we investigate the trade-off between expressiveness and latency in MTP within the framework of probabilistic circuits (PCs). Our framework, named MTPC, allows one to explore different ways to encode the joint distributions over future tokens by selecting different circuit architectures, generalising classical models such as (hierarchical) mixture models, hidden Markov models and tensor networks. We show the efficacy of MTPC by retrofitting existing byte-level LLMs, such as EvaByte. Our experiments show that, when combined with speculative decoding, MTPC significantly speeds up generation compared to MTP with independence assumptions, while guaranteeing to retain the performance of the original verifier LLM. We also rigorously study the optimal trade-off between expressiveness and latency when exploring the possible parameterisations of MTPC, such as PC architectures and partial layer sharing between the verifier and draft LLMs.@misc{grivas2025fast,
title={Fast and Expressive Multi-Token Prediction with Probabilistic Circuits},
author={Andreas Grivas and Lorenzo Loconte and Emile van Krieken and Piotr Nawrot and Yu Zhao and Euan Wielewski and Pasquale Minervini and Edoardo Ponti and Antonio Vergari},
year={2025},
eprint={2511.11346},
archivePrefix={arXiv},
primaryClass={cs.LG}}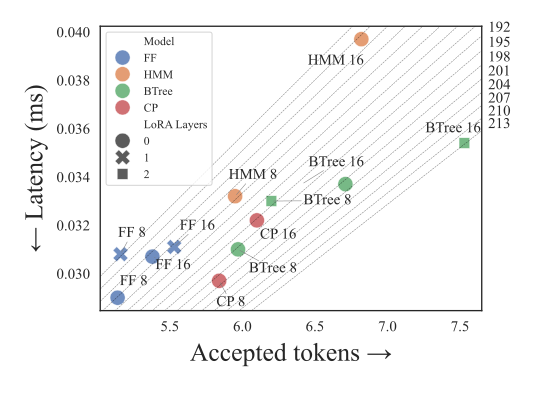
- tl;dr: We show that LLMs' subtraction accuracy significantly lags behind addition, but that instruction tuning can largely fix this weakness.[ paper | bibtex | abstract ]
We present a systematic study of subtraction in large language models (LLMs). While prior benchmarks emphasize addition and multiplication, subtraction has received comparatively little attention despite being structurally distinct as a non-commutative operation. We evaluate eight pretrained LLMs spanning four families on addition and subtraction problems. Our experiments reveal that subtraction accuracy lags behind addition by a wide margin. We find that the errors for (a - b) are concentrated in cases where (a < b). In such cases, LLMs frequently produce the correct magnitude but omit the negative sign. Probing analyses show that LLMs internally encode whether results should be negative, yet this information is often not reflected in generated outputs. We further test well-known techniques such as few-shot learning and instruction-tuning to see if they can improve the LLMs' performance. Our results suggest that while few-shot prompting yields modest gains, the instruction-tuned models achieve near-perfect accuracies in generating the negative sign. Together, these findings provide a clearer characterization of the limitations and recoverability of LLMs' arithmetic capabilities in subtraction.@misc{jobanputra2025llmssubtractnumbers, title={Can LLMs subtract numbers?}, author={Mayank Jobanputra and Nils Philipp Walter and Maitrey Mehta and Blerta Veseli and Evan Parker Kelly Chapple and Yifan Wang and Sneha Chetani and Ellie Pavlick and Antonio Vergari and Vera Demberg}, year={2025}, eprint={2511.02795}, archivePrefix={arXiv}, primaryClass={cs.LG}, url={https://arxiv.org/abs/2511.02795}, }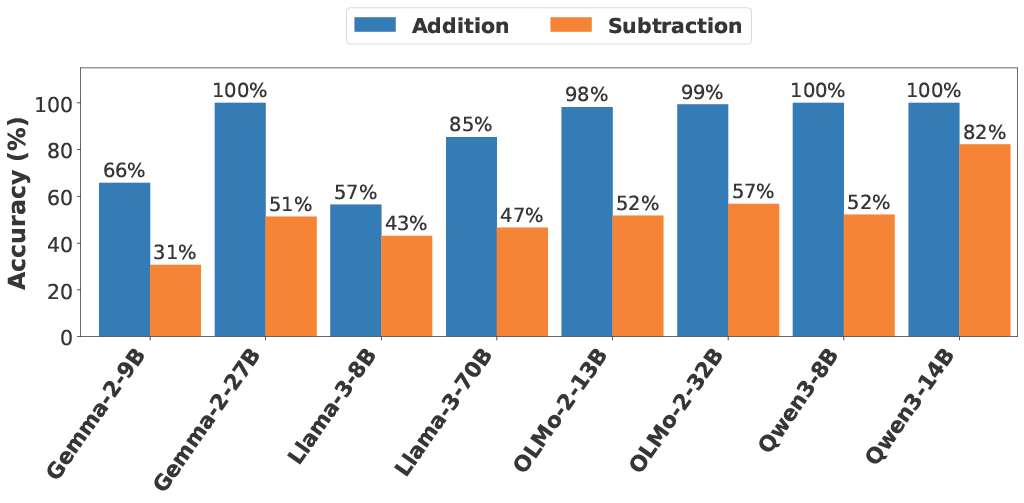
- tl;dr: We prove that neurosymbolic predictors with the independence assumption cannot be reasoning shortcut aware for the vast majority of problems.[ paper | code | bibtex | abstract ]
The ubiquitous independence assumption among symbolic concepts in neurosymbolic (NeSy) predictors is a convenient simplification: NeSy predictors use it to speed up probabilistic reasoning. Recent works like van Krieken et al. (2024) and Marconato et al. (2024) argued that the independence assumption can hinder learning of NeSy predictors and, more crucially, prevent them from correctly modelling uncertainty. There is, however, scepticism in the NeSy community around the scenarios in which the independence assumption actually limits NeSy systems (Faronius and Dos Martires, 2025). In this work, we settle this question by formally showing that assuming independence among symbolic concepts entails that a model can never represent uncertainty over certain concept combinations. Thus, the model fails to be aware of reasoning shortcuts, i.e., the pathological behaviour of NeSy predictors that predict correct downstream tasks but for the wrong reasons.@inproceedings{ krieken2025neurosymbolic, title={Neurosymbolic Reasoning Shortcuts under the Independence Assumption}, author={Emile van Krieken and Pasquale Minervini and Edoardo Ponti and Antonio Vergari}, booktitle={19th International Conference on Neurosymbolic Learning and Reasoning}, year={2025}, url={https://openreview.net/forum?id=ifoKXDf1KS} }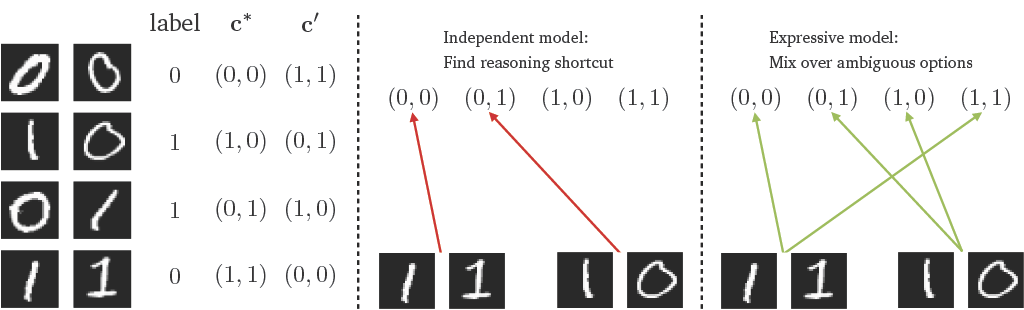
- tl;dr: We integrate discrete diffusion models with neurosymbolic predictors for scalable and calibrated learning and reasoning.[ paper | code | bibtex | abstract ]
Neurosymbolic (NeSy) predictors combine neural perception with symbolic reasoning to solve tasks like visual reasoning. However, standard NeSy predictors assume conditional independence between the symbols they extract, thus limiting their ability to model interactions and uncertainty --- often leading to overconfident predictions and poor out-of-distribution generalisation. To overcome the limitations of the independence assumption, we introduce neurosymbolic diffusion models (NeSyDMs), a new class of NeSy predictors that use discrete diffusion to model dependencies between symbols. Our approach reuses the independence assumption from NeSy predictors at each step of the diffusion process, enabling scalable learning while capturing symbol dependencies and uncertainty quantification. Across both synthetic and real-world benchmarks — including high-dimensional visual path planning and rule-based autonomous driving — NeSyDMs achieve state-of-the-art accuracy among NeSy predictors and demonstrate strong calibration.@inproceedings{ krieken2025neurosymbolic, title={Neurosymbolic Diffusion Models}, author={Emile van Krieken and Pasquale Minervini and Edoardo Ponti and Antonio Vergari}, booktitle={The Thirty-ninth Annual Conference on Neural Information Processing Systems}, year={2025}, url={https://openreview.net/forum?id=HfdzglsZQH} }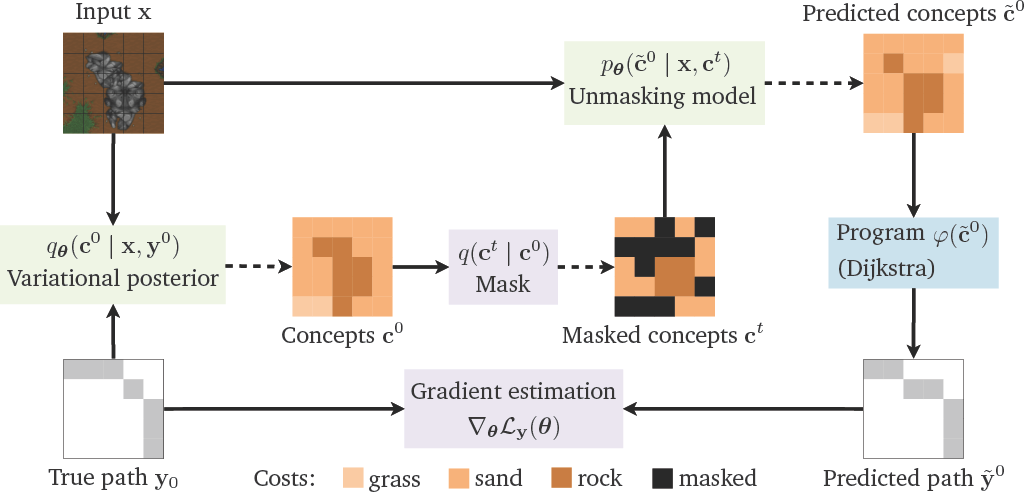
- tl;dr: We highlight how common benchmarks for complex query answering with neural models are skewed towards 'simple' queries and propose new more challenging benchmarks that solve this issue.[ paper | code | bibtex | abstract ]
Complex query answering (CQA) on knowledge graphs (KGs) is gaining momentum as a challenging reasoning task. In this paper, we show that the current benchmarks for CQA might not be as complex as we think, as the way they are built distorts our perception of progress in this field. For example, we find that in these benchmarks most queries (up to 98% for some query types) can be reduced to simpler problems, e.g., link prediction, where only one link needs to be predicted. The performance of state-of-the-art CQA models drops significantly when such models are evaluated on queries that cannot be reduced to easier types. Thus, we propose a set of more challenging benchmarks, composed of queries that require models to reason over multiple hops and better reflect the construction of real-world KGs. In a systematic empirical investigation, the new benchmarks show that current methods leave much to be desired from current CQA methods.@inproceedings{gregucci2025cqa, title={Is Complex Query Answering Really Complex?}, author={Gregucci, Cosimo and Xiong, Bo and Hernández, Daniel and Loconte, Lorenzo and Minervini, Pasquale and Staab, Steffen and Vergari, Antonio}, booktitle={ICML}, year={2025} }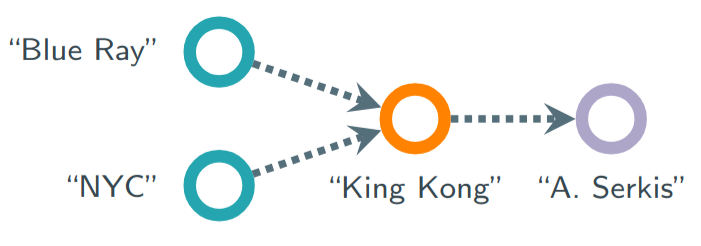
- tl;dr: The performance gap between match-based and LLM-based code evaluation metrics in assessing the code functional equivalence is minimal.[ paper | bibtex | abstract ]
Code-LLMs, LLMs pre-trained on large code corpora, have shown great progress in learning rich representations of the structure and syntax of code, successfully using it to generate or classify code fragments. At the same time, understanding if they are able to do so because they capture code semantics, and how well, is still an open question. In this paper, we tackle this problem by introducing SeqCoBench, a benchmark for systematically assessing how Code-LLMs can capture code functional equivalence. SeqCoBench contains over 20 code transformations that either preserve or alter the semantics of Python programs. We conduct extensive evaluations in different settings, including zero-shot and parameter-efficient finetuning methods on state-of-the-art (Code-)LLMs to see if they can discern semantically equivalent or different pairs of programs in SeqCoBench. We find that the performance gap between these LLMs and classical match-based retrieval scores is minimal, with both approaches showing a concerning lack of depth in understanding code semantics.@inproceedings{maveli-etal-2025-large, title={What can Large Language Models Capture about Code Functional Equivalence?}, author={Maveli, Nickil and Vergari, Antonio and Cohen, Shay B}, editor= {Chiruzzo, Luis and Ritter, Alan and Wang, Lu}, booktitle={Findings of the Association for Computational Linguistics: NAACL 2025}, month= {apr}, year= {2025}, address= {Albuquerque, New Mexico}, publisher= {Association for Computational Linguistics} }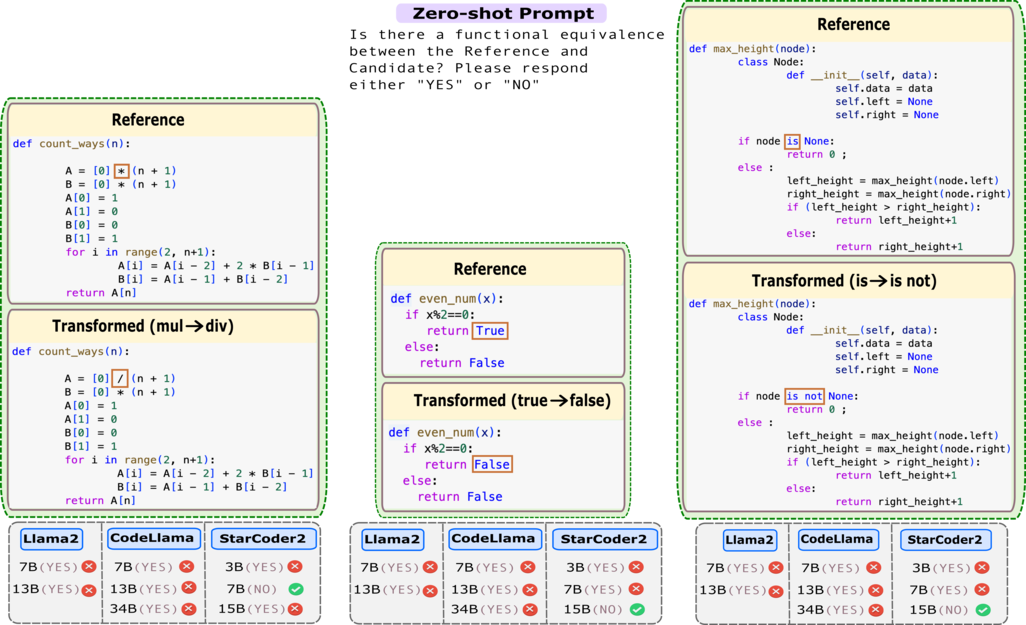
- tl;dr: We motivate the use of subtractive mixture models as proposals for importance sampling and derive a scalable estimator that exploits the decomposition of a subtractive mixture model into a difference of two monotonic mixtures.[ paper | bibtex | abstract ]
Many Monte Carlo (MC) and importance sampling (IS) methods use mixture models (MMs) for their simplicity and ability to capture multimodal distributions. Recently, subtractive mixture models (SMMs), i.e. MMs with negative coefficients, have shown greater expressiveness and success in generative modeling. However, their negative parameters complicate sampling, requiring costly auto-regressive techniques or accept-reject algorithms that do not scale in high dimensions. In this work, we use the difference representation of SMMs to construct an unbiased IS estimator ($\Delta$Ex) that removes the need to sample from the SMM, enabling high-dimensional expectation estimation with SMMs. In our experiments, we show that $\Delta$Ex can achieve comparable estimation quality to auto-regressive sampling while being considerably faster in MC estimation. Moreover, we conduct initial experiments with $\Delta$Ex using hand-crafted proposals, gaining first insights into how to construct safe proposals for $\Delta$Ex.@article{zellinger2025scalable, title={Scalable Expectation Estimation with Subtractive Mixture Models}, author={Zellinger, Lena and Branchini, Nicola and Elvira, V{\'\i}ctor and Vergari, Antonio}, journal={arXiv preprint arXiv:2503.21346}, year={2025} }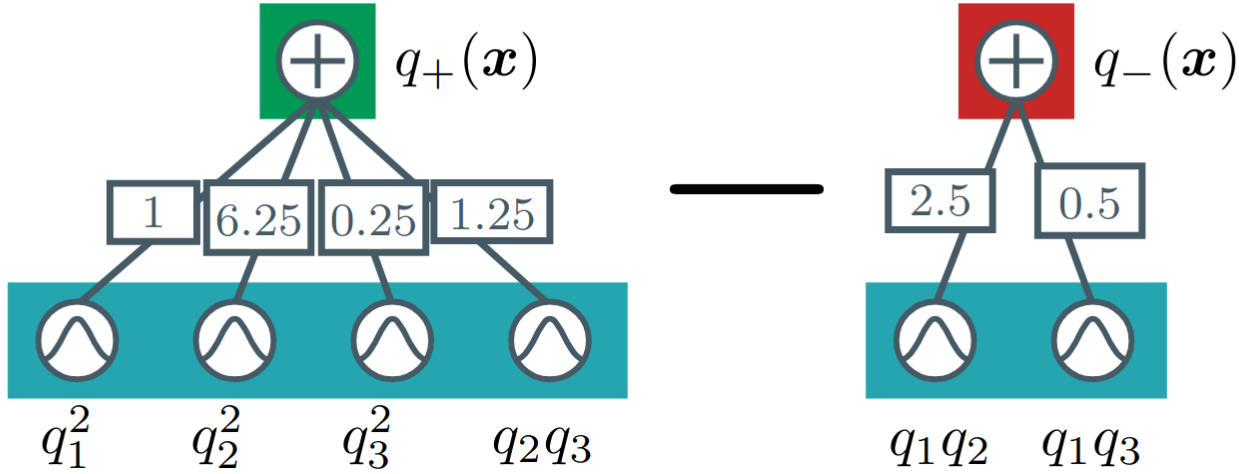
- tl;dr: Our paper introducing PAL, a neurosymbolic layer for algebraic constraint satisfaction, got accepted at UAI 2025 as an oral.[ paper | bibtex | abstract ]
In safety-critical applications, guaranteeing the satisfaction of constraints over continuous environments is crucial, e.g., an autonomous agent should never crash into obstacles or go off-road. Neural models struggle in the presence of these constraints, especially when they involve intricate algebraic relationships. To address this, we introduce a differentiable probabilistic layer that guarantees the satisfaction of non-convex algebraic constraints over continuous variables. This probabilistic algebraic layer (PAL) can be seamlessly plugged into any neural architecture and trained via maximum likelihood without requiring approximations. PAL defines a distribution over conjunctions and disjunctions of linear inequalities, parameterized by polynomials. This formulation enables efficient and exact renormalization via symbolic integration, which can be amortized across different data points and easily parallelized on a GPU. We showcase PAL and our integration scheme on a number of benchmarks for algebraic constraint integration and on real-world trajectory data.@article{kurscheidt2025probabilistic, title={A probabilistic neuro-symbolic layer for algebraic constraint satisfaction}, author={Kurscheidt, Leander and Morettin, Paolo and Sebastiani, Roberto and Passerini, Andrea and Vergari, Antonio}, journal={arXiv preprint arXiv:2503.19466}, year={2025} }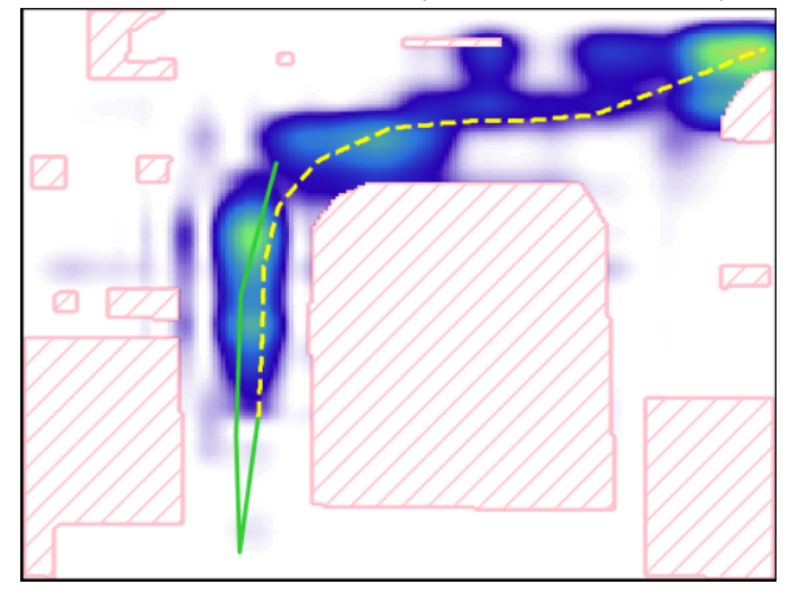
- tl;dr: How can we sensibly aggregate and compare heterogeneous objectives to retrieve the optimal trade-off model the user expects to get? We show that many areas in ML yield biased results due to ignoring this deceptively simple question, and provide a method to overcome these issues by simply re-ranking our objectives before aggregating them.[ paper | bibtex | abstract ]
As machine learning (ML) practitioners, we often have hundreds of (trained) ML models at hand from which we need to choose one, based on various objectives such as accuracy, robustness, fairness, scalability, etc. However, how to compare, aggregate and, ultimately, trade-off these objectives is usually a time-consuming task that requires of expert knowledge, as they may be measured in different units or scales. In this work, we investigate how objectives can be automatically normalized and aggregated to systematically navigate their Pareto front. To do so, we make incomparable objectives comparable using their CDFs, approximated by their relative rankings. As a result, we can aggregate them while matching user-specific preferences, allowing practitioners to meaningfully navigate and search for models in the Pareto front. We demonstrate the potential impact of our approach, COPA, in both model selection and benchmarking tasks across diverse ML areas such as fair ML, domain generalization, AutoML and foundation models, where classical ways to normalize and aggregate objectives fall short.@article{javaloy2025copa, title={COPA: Comparing the incomparable in multi-objective model evaluation}, author={Javaloy, Adri{\'a}n and Vergari, Antonio and Valera, Isabel}, journal={arXiv preprint arXiv:2503.14321}, year={2025} }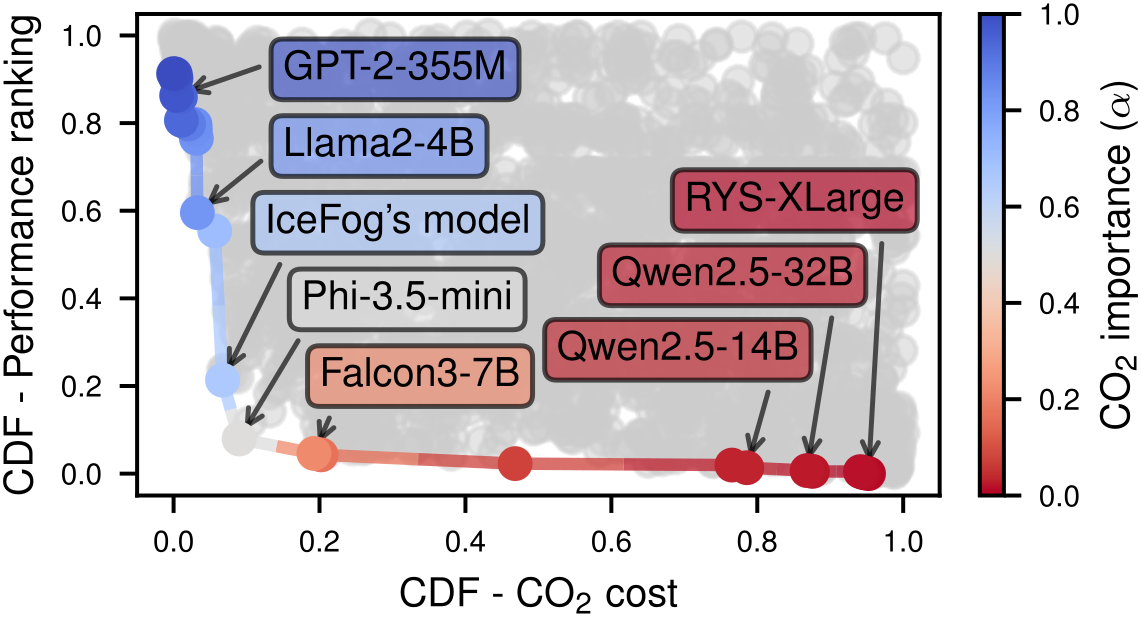
- tl;dr: We investigate the connections between tensor factorizations and circuits: how the literature of the former can benefit from the theory about the latter, and how we can scale the latter with the former.[ paper | bibtex | abstract ]
This paper establishes a rigorous connection between circuit representations and tensor factorizations, two seemingly distinct yet fundamentally related areas. By connecting these fields, we highlight a series of opportunities that can benefit both communities. Our work generalizes popular tensor factorizations within the circuit language, and unifies various circuit learning algorithms under a single, generalized hierarchical factorization framework. Specifically, we introduce a modular 'Lego block' approach to build tensorized circuit architectures. This, in turn, allows us to systematically construct and explore various circuit and tensor factorization models while maintaining tractability. This connection not only clarifies similarities and differences in existing models, but also enables the development of a comprehensive pipeline for building and optimizing new circuit/tensor factorization architectures. We show the effectiveness of our framework through extensive empirical evaluations, and highlight new research opportunities for tensor factorizations in probabilistic modeling.@article{ loconte2025what, title={What is the Relationship between Tensor Factorizations and Circuits (and How Can We Exploit it)?}, author={Lorenzo Loconte and Antonio Mari and Gennaro Gala and Robert Peharz and Cassio de Campos and Erik Quaeghebeur and Gennaro Vessio and Antonio Vergari}, journal={Transactions on Machine Learning Research}, issn={2835-8856}, year={2025}, url={https://openreview.net/forum?id=Y7dRmpGiHj}, note={Featured Certification} }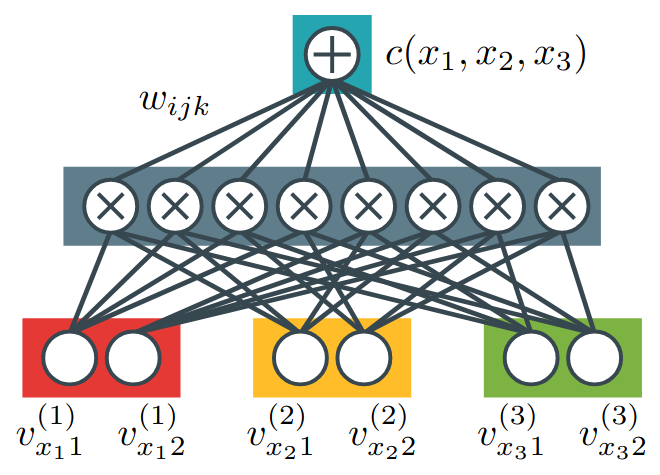
- tl;dr: We introduce Autoencoding Probabilistic Circuits, a novel hybrid framework leveraging tractable probabilistic circuit encoders and neural decoders to learn explicit probabilistic embeddings end-to-end.[ paper | bibtex | abstract ]
Probabilistic Circuits (PCs) enable exact tractable inference, yet their application to representation learning remains underexplored. We introduce Autoencoding Probabilistic Circuits (APCs), a novel framework leveraging PC tractability to explicitly model probabilistic embeddings. APCs jointly model data and latent representations, obtaining embeddings via probabilistic inference using a PC encoder, which is integrated with a neural decoder in an end-to-end trainable hybrid architecture enabled by differentiable sampling. Empirical evaluations demonstrate APCs outperform existing PC-based autoencoding methods in reconstruction quality, generate embeddings competitive with neural autoencoders, and exhibit superior robustness to missing data without requiring imputation. These results establish APCs as a powerful and flexible representation learning method, exploiting PC inference capabilities for robust applications including out-of-distribution detection and knowledge distillation.@inproceedings{ braun2025autoencoding, title={Autoencoding Probabilistic Circuits}, author={Steven Braun and Sahil Sidheekh and Sriraam Natarajan and Antonio Vergari and Martin Mundt and Kristian Kersting}, booktitle={Eighth Workshop on Tractable Probabilistic Modeling}, year={2025}, url={https://openreview.net/forum?id=zgxp6sNpie} }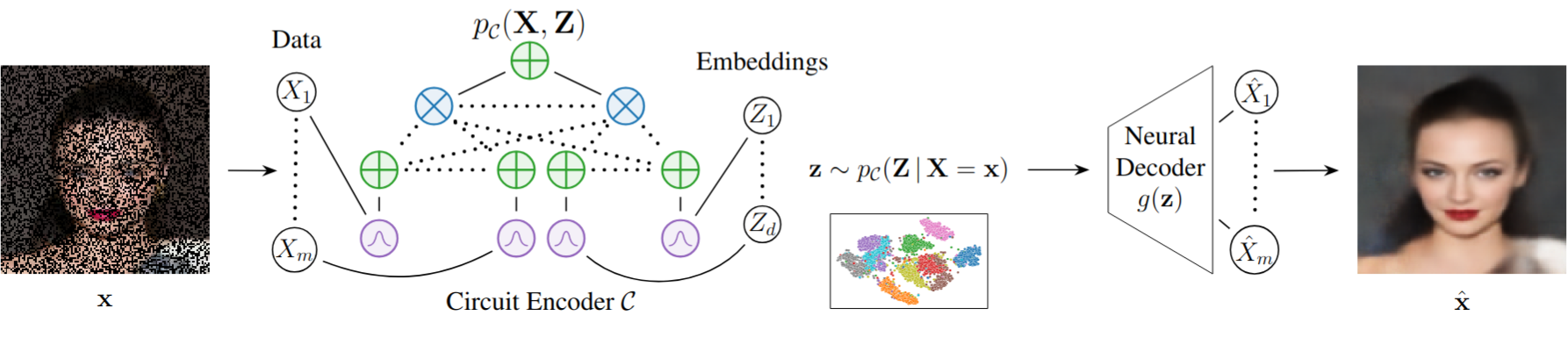
- tl;dr: We introduce a training objective based on principled probabilistic reasoning that teaches a LLM to be logically consistent with a set of external facts and rules, allowing to extrapolate to unseen but semantically similar factual knowledge.[ paper | bibtex | abstract ]
Large language models (LLMs) are a promising venue for natural language understanding and generation tasks. However, current LLMs are far from reliable: they are prone to generate non-factual information and, more crucially, to contradict themselves when prompted to reason about relations between real entities of the world. These problems are currently addressed with large scale fine-tuning or by delegating consistent reasoning to external tools. In this work, we strive for a middle ground and leverage a training objective based on a principled neuro-symbolic loss that teaches a LLM to be consistent with external knowledge in the form of a set of facts and rules. Fine-tuning with such a loss on a limited set of facts enables our LLMs to be more logically consistent than previous baselines for a given constraint. Our approach also allows to easily combine multiple logical constraints at once in a principled way, delivering LLMs that are more consistent w.r.t. all the selected rules. Moreover, our method allows LLMs to extrapolate to unseen but semantically similar factual knowledge, represented in unseen datasets, more systematically.@inproceedings{calanzone2025locolm, title={Towards Logically Consistent Language Models via Probabilistic Reasoning}, author={Diego Calanzone, Stefano Teso, Antonio Vergari}, booktitle={ICLR}, year={2025} }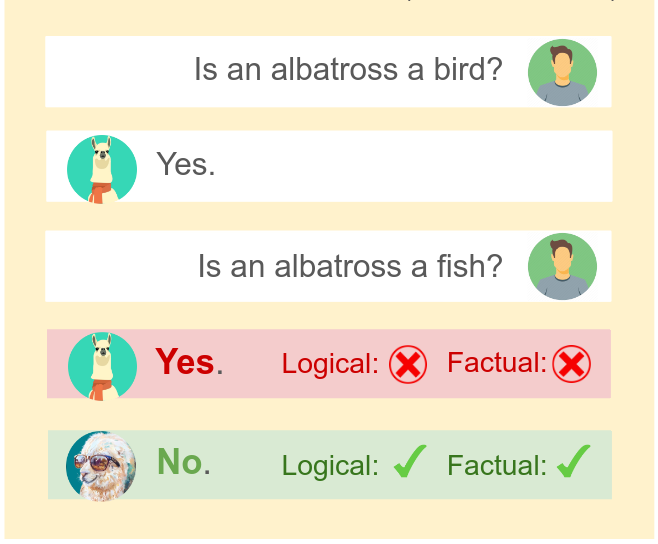
- tl;dr: We theoretically prove an expressiveness limitation of deep subtractive mixture models learned by squaring circuits. To overcome this limitation, we propose sum of squares circuits and build an expressiveness hierarchy around them, allowing us to unify and separate many tractable probabilistic models.[ paper | code | bibtex | abstract ]
Designing expressive generative models that support exact and efficient inference is a core question in probabilistic ML. Probabilistic circuits (PCs) offer a framework where this tractability-vs-expressiveness trade-off can be analyzed theoretically. Recently, squared PCs encoding subtractive mixtures via negative parameters have emerged as tractable models that can be exponentially more expressive than monotonic PCs, i.e., PCs with positive parameters only. In this paper, we provide a more precise theoretical characterization of the expressiveness relationships among these models. First, we prove that squared PCs can be less expressive than monotonic ones. Second, we formalize a novel class of PCs -- sum of squares PCs -- that can be exponentially more expressive than both squared and monotonic PCs. Around sum of squares PCs, we build an expressiveness hierarchy that allows us to precisely unify and separate different tractable model classes such as Born Machines and PSD models, and other recently introduced tractable probabilistic models by using complex parameters. Finally, we empirically show the effectiveness of sum of squares circuits in performing distribution estimation.@inproceedings{loconte2024sos,
title={Sum of Squares Circuits},
author={Lorenzo Loconte and Stefan Mengel and Antonio Vergari},
year={2025},
booktitle={The 39th Annual AAAI Conference on Artificial Intelligence}}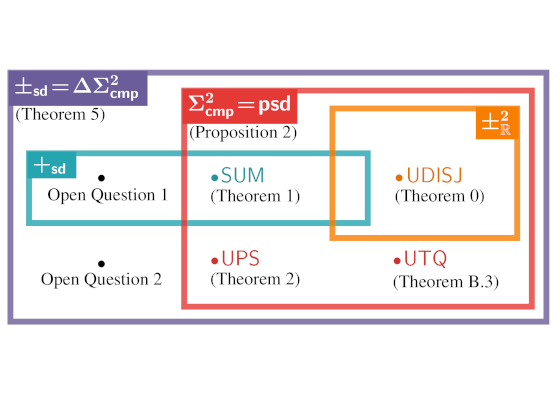
- tl;dr: Inspired by canonical forms in tensor networks, we devise sufficient conditions to ensure squared circuits are already normalized and then devise a more efficient marginalization algorithm.[ paper | bibtex | abstract ]
Squared tensor networks (TNs) and their generalization as parameterized computational graphs -- squared circuits -- have been recently used as expressive distribution estimators in high dimensions. However, the squaring operation introduces additional complexity when marginalizing variables or computing the partition function, which hinders their usage in machine learning applications. Canonical forms of popular TNs are parameterized via unitary matrices as to simplify the computation of particular marginals, but cannot be mapped to general circuits since these might not correspond to a known TN. Inspired by TN canonical forms, we show how to parameterize squared circuits to ensure they encode already normalized distributions. We then use this parameterization to devise an algorithm to compute any marginal of squared circuits that is more efficient than a previously known one. We conclude by formally showing the proposed parameterization comes with no expressiveness loss for many circuit classes.@misc{loconte2024faster,
title={On Faster Marginalization with Squared Circuits via Orthonormalization},
author={Lorenzo Loconte and Antonio Vergari},
year={2024},
eprint={2412.07883},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2412.07883}}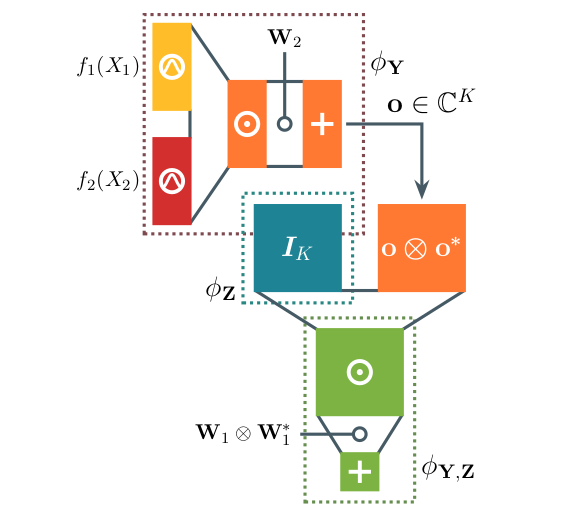
- tl;dr: We scale continuous latent variable mixtures and adapt them to have intricate dependencies, obtaining state-of-the-art likelihoods for tractable models[ paper | bibtex | abstract ]
Probabilistic integral circuits (PICs) have been recently introduced as probabilistic models enjoying the key ingredient behind expressive generative models: continuous latent variables (LVs). PICs are symbolic computational graphs defining continuous LV models as hierarchies of functions that are summed and multiplied together, or integrated over some LVs. They are tractable if LVs can be analytically integrated out, otherwise they can be approximated by tractable probabilistic circuits (PC) encoding a hierarchical numerical quadrature process, called QPCs. So far, only tree-shaped PICs have been explored, and training them via numerical quadrature requires memory-intensive processing at scale. In this paper, we address these issues, and present: (i) a pipeline for building DAG-shaped PICs out of arbitrary variable decompositions, (ii) a procedure for training PICs using tensorized circuit architectures, and (iii) neural functional sharing techniques to allow scalable training. In extensive experiments, we showcase the effectiveness of functional sharing and the superiority of QPCs over traditional PCs.@inproceedings{gala2024scaling, title={Scaling Continuous Latent Variable Models as Probabilistic Integral Circuits}, author={Gala, Gennaro and de Campos, Cassio and Vergari, Antonio and Quaeghebeur, Erik}, booktitle={NeurIPS}, year={2024} }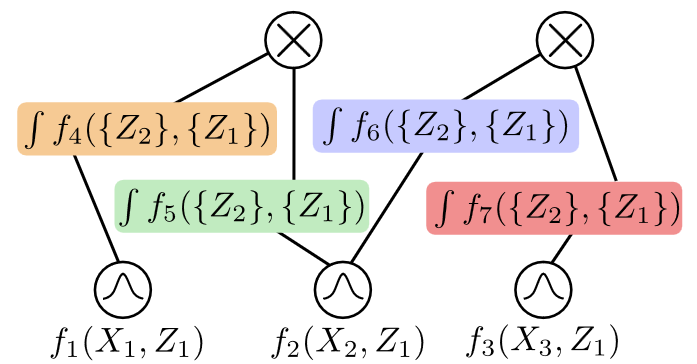
- tl;dr: How to evaluate if neuro-symbolic systems are learning the right concepts or are falling prey of resoning shortcuts?[ paper | code | bibtex | abstract ]
The advent of powerful neural classifiers has increased interest in problems that require both learning and reasoning. These problems are critical for understanding important properties of models, such as trustworthiness, generalization, interpretability, and compliance to safety and structural constraints. However, recent research observed that tasks requiring both learning and reasoning on background knowledge often suffer from reasoning shortcuts (RSs): predictors can solve the downstream reasoning task without associating the correct concepts to the high-dimensional data. To address this issue, we introduce rsbench, a comprehensive benchmark suite designed to systematically evaluate the impact of RSs on models by providing easy access to highly customizable tasks affected by RSs. Furthermore, rsbench implements common metrics for evaluating concept quality and introduces novel formal verification procedures for assessing the presence of RSs in learning tasks. Using rsbench, we highlight that obtaining high quality concepts in both purely neural and neuro-symbolic models is a far-from-solved problem.@inproceedings{bortolotti2024benchmark, title={A Benchmark Suite for Systematically Evaluating Reasoning Shortcuts}, author={Bortolotti, Samuele and Marconato, Emanuele and Carraro, Tommaso and Morettin, Paolo and van Krieken, Emile and Vergari, Antonio and Teso, Stefano and Passerini, Andrea}, booktitle={NeurIPS 2024 Datasets & Benchmarks track}, year={2024} }
- tl;dr: Can LLMs understand, reason about and generate text by operating only on perceptual information such as pixels? We build PIXAR, the first generative pixel-based LLM to answer it.[ paper | code | bibtex | abstract ]
Recent work showed the possibility of building open-vocabulary large language models (LLMs) that directly operate on pixel representations. These models are implemented as autoencoders that reconstruct masked patches of rendered text. However, these pixel-based LLMs are limited to discriminative tasks (e.g., classification) and, similar to BERT, cannot be used to generate text. Therefore, they cannot be used for generative tasks such as free-form question answering. In this work, we introduce PIXAR, the first pixel-based autoregressive LLM that performs text generation. Consisting of only a decoder, PIXAR can perform free-form generative tasks while keeping the number of parameters on par with previous encoder-decoder models. Furthermore, we highlight the challenges of generating text as non-noisy images and show this is due to using a maximum likelihood objective. To overcome this problem, we propose an adversarial pretraining stage that improves the readability and accuracy of PIXAR by 8.1 on LAMBADA and 8.5 on bAbI--- making it comparable to GPT-2 on text generation tasks. This paves the way to build open-vocabulary LLMs that operate on perceptual input only and calls into question the necessity of the usual symbolic input representation, i.e., text as (sub)tokens.@inproceedings{tai2024pixar,
title={PIXAR: Auto-Regressive Language Modeling in Pixel Space},
author={Yintao Tai, Xiyang Liao, Alessandro Suglia, Antonio Vergari,
booktitle={Findings of the Association for Computational Linguistics: ACL 2024},
year={2024} } - tl;dr: NeSy models can suffer from reasoning shortcuts, and to make them shortcut-aware, we sprinkle a pinch of Bayes to quantify the uncertainty over the extracted concepts, showing it is correlated to the presence of reasoning shortcuts.[ paper | code | bibtex | abstract ]
Neuro-Symbolic (NeSy) predictors that conform to symbolic knowledge - encoding, e.g., safety constraints - can be affected by Reasoning Shortcuts (RSs): They learn concepts consistent with the symbolic knowledge by exploiting unintended semantics. RSs compromise reliability and generalization and, as we show in this paper, they are linked to NeSy models being overconfident about the predicted concepts. Unfortunately, the only trustworthy mitigation strategy requires collecting costly dense supervision over the concepts. Rather than attempting to avoid RSs altogether, we propose to ensure NeSy models are aware of the semantic ambiguity of the concepts they learn, thus enabling their users to identify and distrust low-quality concepts. Starting from three simple desiderata, we derive bears (BE Aware of Reasoning Shortcuts), an ensembling technique that calibrates the model's concept-level confidence without compromising prediction accuracy, thus encouraging NeSy architectures to be uncertain about concepts affected by RSs. We show empirically that bears improves RS-awareness of several state-of-the-art NeSy models, and also facilitates acquiring informative dense annotations for mitigation purposes.@inproceedings{marconato2024bears,
title={BEARS Make Neuro-Symbolic Models Aware of their Reasoning Shortcuts},
author={Emanuele Marconato, Samuele Bortolotti, Emile van Krieken, Antonio Vergari, Andrea Passerini, Stefano Teso,
booktitle={Uncertainty in Artificial Intelligence (UAI)},
year={2024} }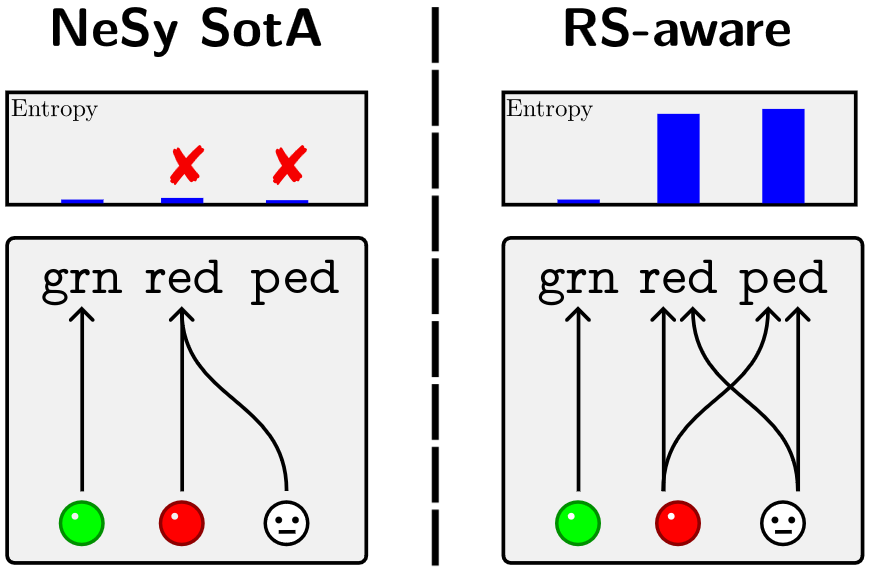
- tl;dr: We theoretically analyze the common assumption that many NeSy models -- from the semantic loss to deep Problog -- do: the independence among terms of a logical formula, and highlight how this biases learning and make some solutions impossible to retrieve.[ paper | bibtex | abstract ]
State-of-the-art neurosymbolic learning systems use probabilistic reasoning to guide neural networks towards predictions that conform to logical constraints over symbols. Many such systems assume that the probabilities of the considered symbols are conditionally independent given the input to simplify learning and reasoning. We study and criticise this assumption, highlighting how it can hinder optimisation and prevent uncertainty quantification. We prove that loss functions bias conditionally independent neural networks to become overconfident in their predictions. As a result, they are unable to represent uncertainty over multiple valid options. Furthermore, we prove that these loss functions are difficult to optimise: they are non-convex, and their minima are usually highly disconnected. Our theoretical analysis gives the foundation for replacing the conditional independence assumption and designing more expressive neurosymbolic probabilistic models.@article{vankrieken2024indep,
title={On the Independence Assumption in Neurosymbolic Learning},
author={Emile van Krieken, Pasquale Minervini, Edoardo M. Ponti, Antonio Vergari,
journal={arXiv preprint arXiv:404.08458},
year={2024} }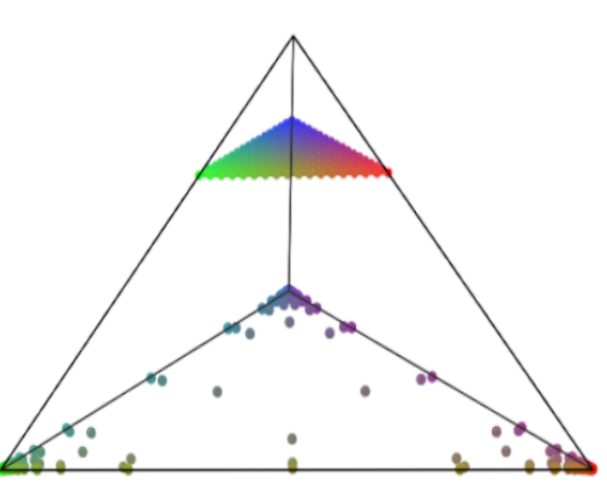
- tl;dr: A novel task in remote sensing for mood disorders, better aligned with the real-world clinical practice, beyond a reductioninst acute illness yes-no binary classification: old and new machine learning challenges[ paper | supplemental | code | bibtex | abstract ]
Mood disorders (MDs) are among the leading causes of disease burden worldwide. Limited specialized care availability remains a major bottleneck thus hindering pre-emptive interventions. MDs manifest with changes in mood, sleep, and motor activity, observable in ecological physiological recordings thanks to recent advances in wearable technology. Therefore, near-continuous and passive collection of physiological data from wearables in daily life, analyzable with machine learning (ML), could mitigate this problem, bringing MDs monitoring outside the clinician’soffice. Previous works predict a single label, either the disease state or a psychometric scale total score. However, clinical practice suggests that the same label may underlie different symptom profiles, requiring specific treatments. Here we bridge this gap by proposing a new task: inferring all items in HDRS and YMRS, the two most widely used standardized scales for assessing MDs symptoms, using physiological data from wearables. To that end, we develop a deep learning pipeline to score the symptoms of a large cohort of MD patients and show that agreement between predictions and assessments by an expert clinician is clinically significant (quadratic Cohen’s κ and macro-average F1 score both of 0.609). While doing so, we investigate several solutions to the ML challenges associated with this task, including multi-task learning, class imbalance, ordinal target variables, and subject-invariant representations. Lastly, we illustrate the importance of testing on out-of distribution samples.@article{corponi2024automated, title={Automated mood disorder symptoms monitoring from multivariate time-series sensory data: Getting the full picture beyond a single number}, author={Corponi, Filippo and Li, Bryan M and Anmella, Gerard and Mas, Ariadna and Pacchiarotti, Isabella and Valentí, Marc and Grande, Iria and Benabarre, Antoni and Garriga, Marina and Vieta, Eduard and Lawrie, Stephen M. and Whalley, Heather C. and Hidalgo-Mazzei, Diego and Vergari, Antonio}, journal={Translational Psychiatry}, volume={14}, number={1}, pages={161}, year={2024}, publisher={Nature Publishing Group UK London} }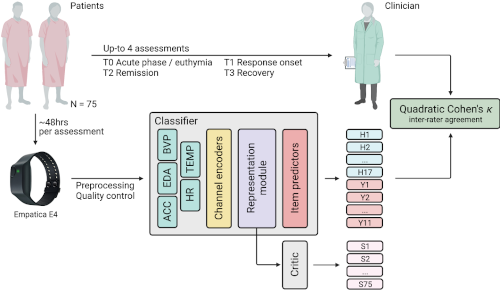
- tl;dr: We introduce a training objective based on principled probabilistic reasoning that teaches a LLM to be logically consistent with a set of external facts and rules, allowing to extrapolate to unseen but semantically similar factual knowledge.[ paper | bibtex | abstract ]
Large language models (LLMs) are a promising venue for natural language understanding and generation tasks. However, current LLMs are far from reliable: they are prone to generate non-factual information and, more crucially, to contradict themselves when prompted to reason about beliefs of the world. These problems are currently addressed with large scale fine-tuning or by delegating consistent reasoning to external tools. In this work, we strive for a middle ground and introduce a training objective based on principled probabilistic reasoning that teaches a LLM to be consistent with external knowledge in the form of a set of facts and rules. Fine-tuning with our loss on a limited set of facts enables our LLMs to be more logically consistent than previous baselines and allows them to extrapolate to unseen but semantically similar factual knowledge more systematically.@inproceedings{calanzone2024locolm, title={Towards Logically Consistent Language Models via Probabilistic Reasoning}, author={Diego Calanzone, Antonio Vergari, Stefano Teso}, booktitle={ICLR 2024 Workshop on Reliable and Responsible Foundation Models}, year={2024} } - tl;dr: We propose DeepGALA as a fast and effective way to estimate uncertainty in deep neural PDE solvers that allows us to capture meaningful uncertainty in out of domain of the PDE solution and in low data regimes with little overhead.[ paper | bibtex | abstract ]
The solution of partial differential equations (PDEs) by deep neural networks trained to satisfy the differential operator has become increasingly popular. While these approaches can lead to very accurate approximations, they tend to be over- confident and fail to capture the uncertainty around the approximation. In this work, we propose a Bayesian treatment to the deep Galerkin method (Sirignano & Spiliopoulos, 2018), a popular neural approach for solving parametric PDEs. In particular, we reinterpret the deep Galerkin method as the maximum a posteriori estimator corresponding to a likelihood term over a fictitious dataset, leading thus to a natural definition of a posterior. Then, we propose to model such posterior via the Laplace approximation, a fast approximation that allows us to capture mean- ingful uncertainty in out of domain interpolation of the PDE solution and in low data regimes with little overhead, as shown in our preliminary experiments.@inproceedings{beltran-jimenez2024galerkin, title={Galerkin meets Laplace: Fast uncertainty estimation in neural PDEs}, author={Christian Jimenez Beltran, Antonio Vergari, Aretha L Teckentrup, Konstantinos C. Zygalakis}, booktitle={ICLR 2024 Workshop on AI4DifferentialEquations}, year={2024} }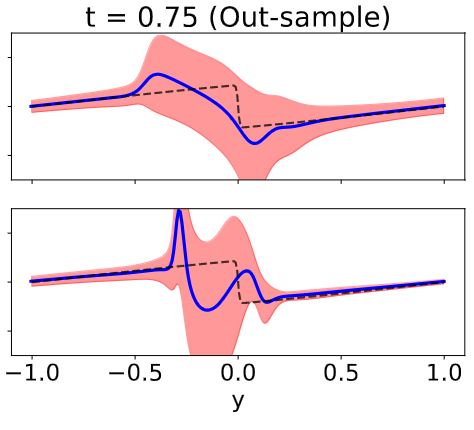
- tl;dr: We cast chemical reaction prediction as algebraic reasoning to evaluate the reasoning capabilities of Transformers and provide a challenging benchmark for it.[ paper | bibtex | abstract ]
While showing impressive performance on various kinds of learning tasks, it is yet unclear whether deep learning models have the ability to robustly tackle reasoning tasks. than by learning the underlying reasoning process that is actually required to solve the tasks. Measuring the robustness of reasoning in machine learning models is challenging as one needs to provide a task that cannot be easily shortcut by exploiting spurious statistical correlations in the data, while operating on complex objects and constraints. reasoning task. To address this issue, we propose ChemAlgebra, a benchmark for measuring the reasoning capabilities of deep learning models through the prediction of stoichiometrically-balanced chemical reactions. ChemAlgebra requires manipulating sets of complex discrete objects -- molecules represented as formulas or graphs -- under algebraic constraints such as the mass preservation principle. We believe that ChemAlgebra can serve as a useful test bed for the next generation of machine reasoning models and as a promoter of their development.@inproceedings{valenti2024chemalgebra,
title={ChemAlgebra: Algebraic Reasoning on Chemical Reactions},
author={Valenti, Andrea and Bacciu, Davide and Vergari, Antonio},
booktitle={WCCI},
year={2024} }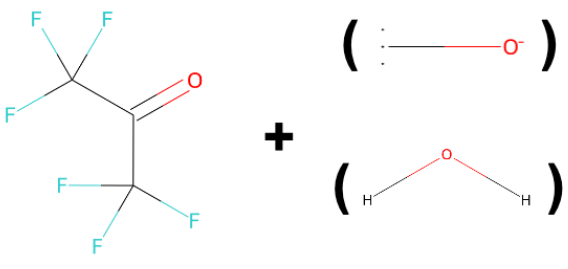
- tl;dr: We create two challenging benchmarks for continual learning (CL) that comprise a sequence of image classification tasks: generalizing from MNIST to (tiny) ImageNet and vice versa, highlighting in a thorough set of experiments that sota CL method fall prey of catastrophic forgetting.[ paper | bibtex | abstract ]
Continual learning (CL) is one of the most promising trends in recent machine learning research. Its goal is to go beyond classical assumptions in machine learning and develop models and learning strategies that present high robustness in dynamic environments. The landscape of CL research is fragmented into several learning evaluation protocols, comprising different learning tasks, datasets, and evaluation metrics. Additionally, the benchmarks adopted so far are still distant from the complexity of real-world scenarios, and are usually tailored to highlight capabilities specific to certain strategies. In such a landscape, it is hard to objectively assess strategies. In this work, we fill this gap for CL on image data by introducing two novel CL benchmarks that involve multiple heterogeneous tasks from six image datasets, with varying levels of complexity and quality. Our aim is to fairly evaluate current state-of-the-art CL strategies on a common ground that is closer to complex real-world scenarios. We additionally structure our benchmarks so that tasks are presented in increasing and decreasing order of complexity -- according to a curriculum -- in order to evaluate if current CL models are able to exploit structure across tasks. We devote particular emphasis to providing the CL community with a rigorous and reproducible evaluation protocol for measuring the ability of a model to generalize and not to forget while learning. Furthermore, we provide an extensive experimental evaluation showing that popular CL strategies, when challenged with our benchmarks, yield sub-par performance, high levels of forgetting, and present a limited ability to effectively leverage curriculum task ordering. We believe that these results highlight the need for rigorous comparisons in future CL works as well as pave the way to design new CL strategies that are able to deal with more complex scenarios.@inproceedings{faber2024m2i2m,
title={From MNIST to ImageNet and Back: Benchmarking Continual Curriculum Learning},
author={Kamil Faber, Dominik Zurek, Marcin Pietron, Nathalie Japkowicz, Antonio Vergari, Roberto Corizzo,
booktitle={Proceedings of the AAAI-22 Workshop on Interactive Machine Learning (IML'22)},
year={2022} }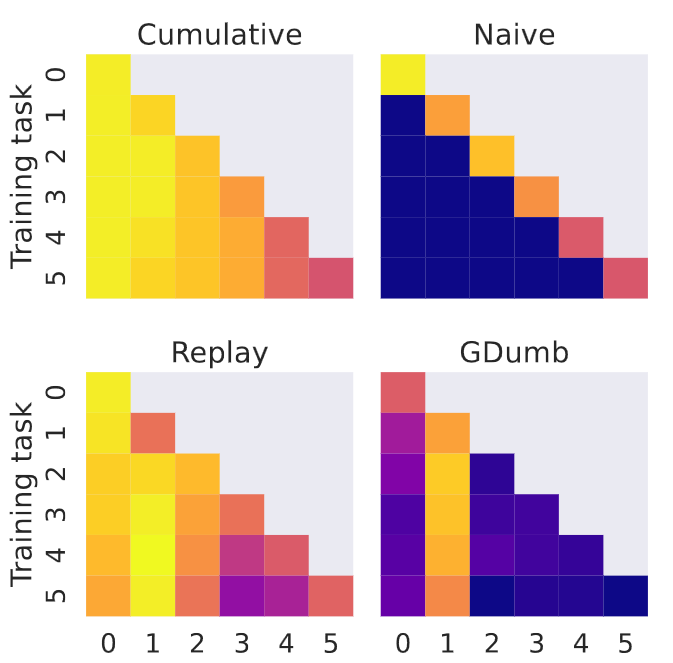
- tl;dr: We represent hierarchical continuous latent variable models as computational graph that allow us to efficiently approximate intractable distributions via recursive quadrature rules[ paper | code | bibtex | abstract ]
Continuous latent variables (LVs) are a key ingredient of many generative models, as they allow modelling expressive mixtures with an uncountable number of components. In contrast, probabilistic circuits (PCs) are hierarchical discrete mixtures represented as computational graphs composed of input, sum and product units. Unlike continuous LV models, PCs provide tractable inference but are limited to discrete LVs with categorical (i.e. unordered) states. We bridge these model classes by introducing probabilistic integral circuits (PICs), a new language of computational graphs that extends PCs with integral units representing continuous LVs. In the first place, PICs are symbolic computational graphs and are fully tractable in simple cases where analytical integration is possible. In practice, we parameterise PICs with light-weight neural nets delivering an intractable hierarchical continuous mixture that can be approximated arbitrarily well with large PCs using numerical quadrature. On several distribution estimation benchmarks, we show that such PIC-approximating PCs systematically outperform PCs commonly learned via expectation-maximization or SGD.@InProceedings{gala2024pic, title = { Probabilistic Integral Circuits }, author = {Gala, Gennaro and de Campos, Cassio and Peharz, Robert and Vergari, Antonio and Quaeghebeur, Erik}, booktitle = {Proceedings of The 27th International Conference on Artificial Intelligence and Statistics}, pages = {2143--2151}, year = {2024}, editor = {Dasgupta, Sanjoy and Mandt, Stephan and Li, Yingzhen}, volume = {238}, series = {Proceedings of Machine Learning Research}, month = {02--04 May}, publisher = {PMLR}, pdf = {https://proceedings.mlr.press/v238/gala24a/gala24a.pdf}, url = {https://proceedings.mlr.press/v238/gala24a.html}, abstract = { Continuous latent variables (LVs) are a key ingredient of many generative models, as they allow modelling expressive mixtures with an uncountable number of components. In contrast, probabilistic circuits (PCs) are hierarchical discrete mixtures represented as computational graphs composed of input, sum and product units. Unlike continuous LV models, PCs provide tractable inference but are limited to discrete LVs with categorical (i.e. unordered) states. We bridge these model classes by introducing probabilistic integral circuits (PICs), a new language of computational graphs that extends PCs with integral units representing continuous LVs. In the first place, PICs are symbolic computational graphs and are fully tractable in simple cases where analytical integration is possible. In practice, we parameterise PICs with light-weight neural nets delivering an intractable hierarchical continuous mixture that can be approximated arbitrarily well with large PCs using numerical quadrature. On several distribution estimation benchmarks, we show that such PIC-approximating PCs systematically outperform PCs commonly learned via expectation-maximization or SGD. } }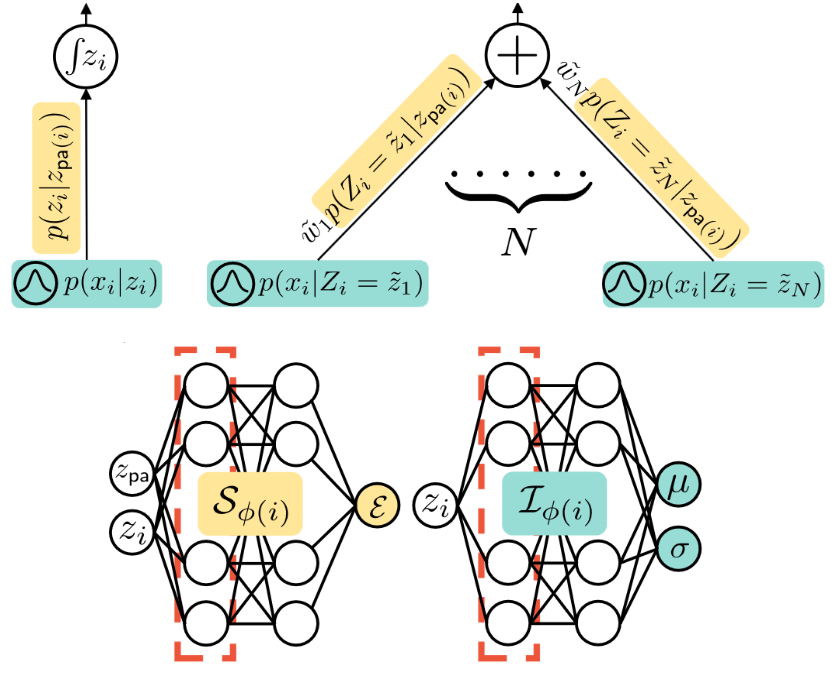
- tl;dr: We propose to build (deep) subtractive mixture models by squaring circuits. We theoretically prove their expressiveness by deriving an exponential lowerbound on the size of circuits with positive parameters only.[ paper | code | bibtex | abstract ]
Mixture models are traditionally represented and learned by adding several distributions as components. Allowing mixtures to subtract probability mass or density can drastically reduce the number of components needed to model complex distributions. However, learning such subtractive mixtures while ensuring they still encode a non-negative function is challenging. We investigate how to learn and perform inference on deep subtractive mixtures by squaring them. We do this in the framework of probabilistic circuits, which enable us to represent tensorized mixtures and generalize several other subtractive models. We theoretically prove that the class of squared circuits allowing subtractions can be exponentially more expressive than traditional additive mixtures; and, we empirically show this increased expressiveness on a series of real-world distribution estimation tasks.@inproceedings{loconte2024subtractive,
title={Subtractive Mixture Models via Squaring: Representation and Learning},
author={Loconte, Lorenzo and Aleksanteri, M. Sladek and Mengel, Stefan and Trapp, Martin and Solin, Arno and Gillis, Nicolas and Vergari, Antonio},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=xIHi5nxu9P}}
- tl;dr: We highlight a weakness of low-rank linear multi-label classifiers: they can have meaningful outputs that cannot be predicted. We design a classifier which guarantees that sparse outputs can be predicted while using less trainable parameters.[ paper | code | bibtex | abstract ]
Sigmoid output layers are widely used in multi-label classification (MLC) tasks, in which multiple labels can be assigned to any input. In many practical MLC tasks, the number of possible labels is in the thousands, often exceeding the number of input features and resulting in a low-rank output layer. In multi-class classification, it is known that such a low-rank output layer is a bottleneck that can result in unargmaxable classes: classes which cannot be predicted for any input. In this paper, we show that for MLC tasks, the analogous sigmoid bottleneck results in exponentially many unargmaxable label combinations. We explain how to detect these unargmaxable outputs and demonstrate their presence in three widely used MLC datasets. We then show that they can be prevented in practice by introducing a Discrete Fourier Transform (DFT) output layer, which guarantees that all sparse label combinations with up to k active labels are argmaxable. Our DFT layer trains faster and is more parameter efficient, matching the F1@k score of a sigmoid layer while using up to 50% fewer trainable parameters. Our code is publicly available at https://github.com/andreasgrv/sigmoid-bottleneck.@inproceedings{grivas2023taming,
title={Taming the Sigmoid Bottleneck: Provably Argmaxable Sparse Multi-Label Classification},
author={Andreas Grivas and Antonio Vergari and Adam Lopez},
booktitle={Proceedings of the 38th Annual AAAI Conference on Artificial Intelligence},
year={2024} }
- tl;dr: KGE models such as CP, RESCAL, TuckER, ComplEx can be re-interpreted as circuits to unlock their generative capabilities, scaling up inference and learning and guaranteeing the satisfaction of logical constraints by design.[ paper | code | bibtex | abstract ]
Some of the most successful knowledge graph embedding (KGE) models for link prediction -- CP, RESCAL, TuckER, ComplEx -- can be interpreted as energy-based models. Under this perspective they are not amenable for exact maximum-likelihood estimation (MLE), sampling and struggle to integrate logical constraints. This work re-interprets the score functions of these KGEs as circuits -- constrained computational graphs allowing efficient marginalisation. Then, we design two recipes to obtain efficient generative circuit models by either restricting their activations to be non-negative or squaring their outputs. Our interpretation comes with little or no loss of performance for link prediction, while the circuits framework unlocks exact learning by MLE, efficient sampling of new triples, and guarantee that logical constraints are satisfied by design. Furthermore, our models scale more gracefully than the original KGEs on graphs with millions of entities.@inproceedings{loconte2023how,
title={How to Turn Your Knowledge Graph Embeddings into Generative Models},
author={Lorenzo Loconte and Nicola Di Mauro and Robert Peharz and Antonio Vergari},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=RSGNGiB1q4}}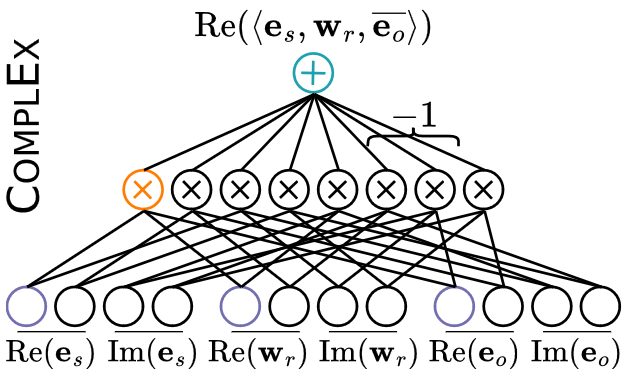
- tl;dr: We analyze causes and mitigation of reasoning shortcuts in neuro-symbolic models, which let them make the right predictions but for the wrong reasons.[ paper | bibtex | abstract ]
Neuro-Symbolic (NeSy) predictive models hold the promise of improved compliance with given constraints, systematic generalization, and interpretability, as they allow to infer labels that are consistent with some prior knowledge by reasoning over high-level concepts extracted from sub-symbolic inputs. It was recently shown that NeSy predictors are affected by reasoning shortcuts: they can attain high accuracy but by leveraging concepts with unintended semantics, thus coming short of their promised advantages. Yet, a systematic characterization of reasoning shortcuts and of potential mitigation strategies is missing. This work fills this gap by characterizing them as unintended optima of the learning objective and identifying four key conditions behind their occurrence. Based on this, we derive several natural mitigation strategies, and analyze their efficacy both theoretically and empirically. Our analysis shows reasoning shortcuts are difficult to deal with, casting doubts on the trustworthiness and interpretability of existing NeSy solutions.@inproceedings{marconato2023shortcuts,
title={Not All Neuro-Symbolic Concepts Are Created Equal: Analysis and Mitigation of Reasoning Shortcuts},
author={Emanuele Marconato, Stefano Teso, Antonio Vergari, Andrea Passerini},
booktitle={arXiv},
year={2023}}
- tl;dr: We disentangle the few structural choices that can characterize the performance of modern circuit architectures in terms of expressiveness and computational complexity.[ paper | bibtex | abstract ]
Tensorizing probabilistic circuits (PCs) -- structured computational graphs capable of efficiently and accurately performing various probabilistic reasoning tasks -- is the go-to way to represent and learn these models. This paper systematically explores the architectural options employed in modern overparameterized PCs, namely RAT-SPNs, EiNets, and HCLTs, and unifies them into a single algorithmic framework. By trying to compress the existing overparameterized layers via low-rank decompositions, we discover alternative parameterizations that possess the same expressive power but are computationally more efficient. This emphasizes the possibility of “mixing & matching” different design choices to create new PCs and helps to disentangle the few ones that really matter.@inproceedings{mari2023lorapc,
title={Unifying and Understanding Overparameterized Circuit Representations via Low-Rank Tensor Decompositions},
author={Antonio Mari, Gennaro Vessio, Antonio Vergari},
booktitle={The 6th Workshop on Tractable Probabilistic Modeling},
year={2023}}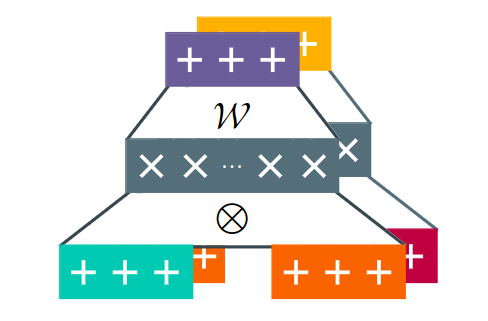
- tl;dr: We propose to build (hierarchical) negative mixture models by squaring circuits. We theoretically prove their expressiveness by deriving an exponential lowerbound on the size of circuits with positive parameters only.[ paper | bibtex | abstract ]
Negative mixture models (NMMs) can potentially be more expressive than classical non-negative ones by allowing negative coefficients, thus greatly reducing the number of components and parameters to fit. However, modeling NMMs features a number of challenges, from ensuring that negative combinations still encode valid densities or masses, to effectively learning them from data. In this paper, we investigate how we can model both shallow and hierarchical NMMs in a generic framework, via squaring. We do so by representing NMMs as probabilistic circuits (PCs) – structured computational graphs that ensure tractability. Then, we show when and how we can represent these squared NMMs as tensorized computational graphs efficiently, while theoretically proving that for certain function classes including negative parameters can exponentially reduce the model size.@inproceedings{loconte2023nmm,
title={Negative Mixture Models via Squaring: Representation and Learning},
author={Lorenzo Loconte and Stefan Mengel and Nicolas Gillis and Antonio Vergari},
booktitle={The 6th Workshop on Tractable Probabilistic Modeling},
year={2023}}
- tl;dr: We design a differentiable layer that can be plugged into any neural network to guarantee that predictions are always consistent with a set of predefined symbolic constraints and can be trained end-to-end.[ paper | supplemental | code | bibtex | abstract ]
We design a predictive layer for structured-output prediction (SOP) that can be plugged into any neural network guaranteeing its predictions are consistent with a set of predefined symbolic constraints. Our Semantic Probabilistic Layer (SPL) can model intricate correlations, and hard constraints, over a structured output space all while being amenable to end-to-end learning via maximum likelihood.SPLs combine exact probabilistic inference with logical reasoning in a clean and modular way, learning complex distributions and restricting their support to solutions of the constraint. As such, they can faithfully, and efficiently, model complex SOP tasks beyond the reach of alternative neuro-symbolic approaches. We empirically demonstrate that SPLs outperform these competitors in terms of accuracy on challenging SOP tasks such as hierarchical multi-label classification, pathfinding and preference learning, while retaining perfect constraint satisfaction.@inproceedings{ahmed2022spl,
author = {Ahmed, Kareem and Teso, Stefano and Chang, Kai-Wei and Van den Broeck, Guy and Vergari, Antonio},
booktitle = {Advances in Neural Information Processing Systems},
editor = {S. Koyejo and S. Mohamed and A. Agarwal and D. Belgrave and K. Cho and A. Oh},
pages = {29944--29959},
publisher = {Curran Associates, Inc.},
title = {Semantic Probabilistic Layers for Neuro-Symbolic Learning},
url = {https://proceedings.neurips.cc/paper_files/paper/2022/file/c182ec594f38926b7fcb827635b9a8f4-Paper-Conference.pdf}, volume = {35},
year = {2022} }
- tl;dr: We study how interactive learning for structured output spaces (with a focus on active learning) can be made efficient and reliable within the framework of probabilistic circuits[ paper | bibtex | abstract ]
In this position paper, we study interactive learning for structured output spaces, with a focus on active learning, in which labels are unknown and must be acquired, and on skeptical learning, in which the labels are noisy and may need relabeling. These scenarios require expressive models that guarantee reliable and efficient computation of probabilistic quantities to measure uncertainty. We identify conditions under which a class of probabilistic models -- which we denote CRISPs -- meet all of these conditions, thus delivering tractable computation of the above quantities while preserving expressiveness. Building on prior work on tractable probabilistic circuits, we illustrate how CRISPs enable robust and efficient active and skeptical learning in large structured output spaces.@inproceedings{teso2022crisps,
title={Efficient and Reliable Probabilistic Interactive Learning with Structured Outputs},
author={Stefano Teso, Antonio Vergari,
booktitle={Proceedings of the AAAI-22 Workshop on Interactive Machine Learning (IML'22)},
year={2022} }
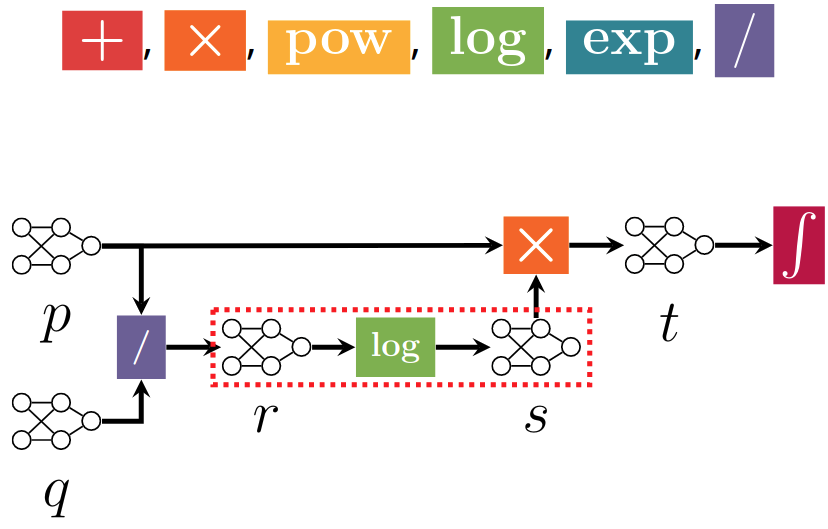
- tl;dr: A systematic framework in which tractable inference routines can be broken down into smaller and composable primitives operating on circuit representations.[ paper | supplemental | code | bibtex | abstract ]
Circuit representations are becoming the lingua franca to express and reason about tractable generative and discriminative models. In this paper, we show how complex inference scenarios for these models that commonly arise in machine learning---from computing the expectations of decision tree ensembles to information-theoretic divergences of sum-product networks---can be represented in terms of tractable modular operations over circuits. Specifically, we characterize the tractability of simple transformations---sums, products, quotients, powers, logarithms, and exponentials---in terms of sufficient structural constraints of the circuits they operate on, and present novel hardness results for the cases in which these properties are not satisfied. Building on these operations, we derive a unified framework for reasoning about tractable models that generalizes several results in the literature and opens up novel tractable inference scenarios.@inproceedings{vergari2021atlas,
author = {Vergari, Antonio and Choi, YooJung and Liu, Anji and Teso, Stefano and Van den Broeck, Guy},
booktitle = {Advances in Neural Information Processing Systems},
editor = {M. Ranzato and A. Beygelzimer and Y. Dauphin and P.S. Liang and J. Wortman Vaughan},
pages = {13189--13201},
publisher = {Curran Associates, Inc.},
title = {A Compositional Atlas of Tractable Circuit Operations for Probabilistic Inference},
url = {https://proceedings.neurips.cc/paper_files/paper/2021/file/6e01383fd96a17ae51cc3e15447e7533-Paper.pdf},
volume = {34},
year = {2021} }